Cracked Labs met en lumière le capitalisme de données
Le Cracked Labs, un institut indépendant autrichien, publie une vaste enquête sur le commerce des données numériques. Un tableau édifiant.
Edward Snowden ne cesse pourtant de vous avertir. Chaque fois que vous cliquez sur un site web depuis votre ordinateur ou votre smartphone, vous déclenchez une grande variété de mécanismes de partage de données cachées réparties entre nombre d’entreprises. Le suivi numérique et le profilage, combinés à la personnalisation, sont non seulement utilisés pour surveiller, mais aussi pour influencer votre comportement. Ils affectent les choix qui vous sont proposés. L’étude Corporate Surveillance in Everyday Life qu’a publié l’institut viennois Cracked Labs le 8 juin fait 93 pages et est extrêmement fouillée. L’organisme indépendant propose un focus sur la partie cachée d’un iceberg fort utile pour tous ceux qui s’alarment sur le commerce de données et signalent les atteintes à la protection de la vie privée. L’étude a été dirigée par Wolfie Christl, déjà auteur en 2016 de Network of Control, qui étend et complète ici ses recherches. Elle examine en particulier les pratiques et le fonctionnement interne des entreprises concernées, les flux cachés, et met en lumière les grands acteurs du secteur. Voici ses principales conclusions.
« Depuis 2007, le lancement du smartphone par Apple et le passage du cap des 30 millions d’utilisateurs par Facebook, les entreprises de publicité en ligne se sont mises à cibler la publicité dirigée vers les utilisateurs d’Internet en fonction de leurs préférences et intérêts individuels. En dix ans, une vaste constellation d’entreprises s’est déployée sur le marché dérégulé et juteux de la commercialisation des données.
« Aujourd’hui, les grandes plateformes, les entreprises de publicité, les courtiers de données, identifient, trient, classent, catégorisent, évaluent et notent les consommateurs des plateformes et des appareils numériques fixes et mobiles. De nombreux aspects de la personnalité d’un individu peuvent être découverts à partir des traces de ses recherches sur le Web, de son historique de navigation, de ses comportements de visionnage vidéo, de ses activités sur les réseaux sociaux ou de ses achats en ligne. (…)
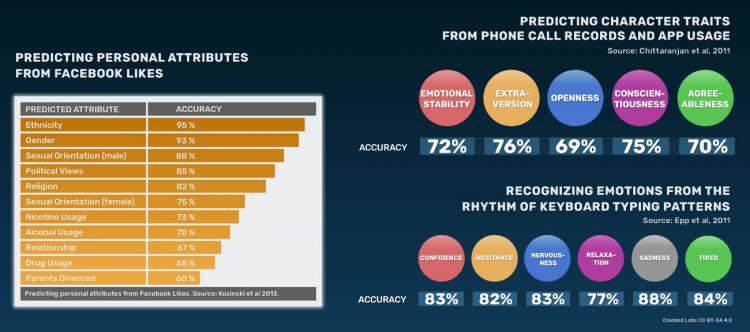
« Les indicateurs personnels sensibles tels que l’appartenance ethnique, les opinions religieuses et politiques, la profession, le niveau de scolarité, le statut des relations, l’orientation sexuelle et ses relations avec l’alcool, la cigarette et l’usage de drogues peuvent par exemple être déduits de manière assez précise de l’analyse du cercle d’amis d’un utilisateur de Facebook. L’analyse des profils des réseaux sociaux peut également prédire les traits de personnalité tels que la stabilité émotionnelle, l’indice de satisfaction, l’impulsivité, les états dépressifs ou les goûts pour certaines sensations.
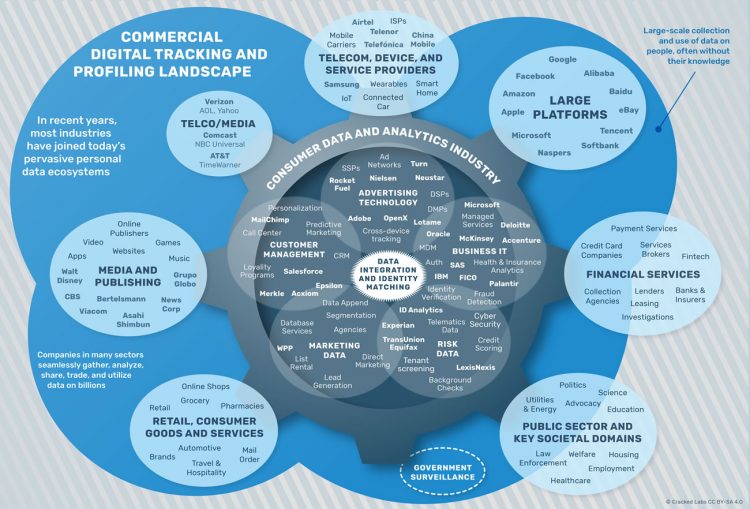
Finance, assurance, santé
« Au-delà des grands acteurs tels que Facebook et Google, des milliers d’autres entreprises de diverses industries partagent et échangent continuellement des profils numériques, combinent et relient les données du Web et des smartphones aux données des clients et aux informations hors ligne accumulées depuis des décennies. Fait alarmant, les données sur les comportements des personnes, les relations sociales et la plupart des moments privés sont de plus en plus appliquées dans des contextes ou à des fins complètement différentes de celles pour lesquelles elles ont été enregistrées. Elles sont même de plus en plus utilisées pour prendre des décisions automatisées sur des personnes dans des domaines de vie cruciaux tels que la finance, les assurances et les services de santé.
« Des start-ups comme Lenddo, Kreditech, Cignifi et ZestFinance utilisent déjà des données provenant de réseaux sociaux, de recherches sur le Web ou de téléphones mobiles, pour calculer la solvabilité de quelqu’un sans utiliser de données relatives aux transactions financières. (…) Le grand assureur Aviva, en collaboration avec la firme de consultants Deloitte, a cherché à prédire les risques individuels de santé, tels que le diabète, le cancer, l’hypertension artérielle et la dépression, pour 60000 de ses demandeurs d’assurance, selon des données des consommateurs traditionnellement utilisées pour le marketing et achetées auprès d’un courtier de données. (…) La société d’analyse de santé GNS Healthcare calcule les risques individuels pour la santé chez les patients en se basant sur une large gamme de données telles que la génomique, les dossiers médicaux, les données de laboratoire, les dispositifs de santé mobiles et le comportement des consommateurs.
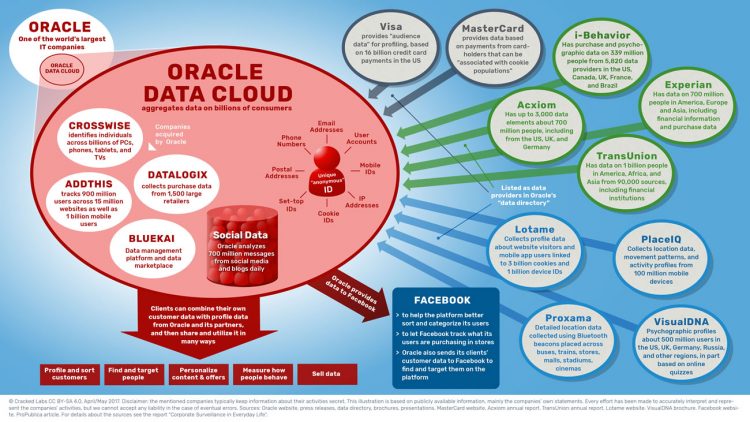
Facebook et Oracle, mastodontes du secteur
« Les données Facebook sont sources de profit dans la mesure où le géant des réseaux sociaux utilise pas moins de 52000 indicateurs personnels pour trier et classer ses 1,9 milliards d’utilisateurs. Pour ce faire, la plateforme analyse les messages, likes, partages, amis, photos, mouvements et d’autres types de comportements. En outre, Facebook achète des données sur ses propres utilisateurs auprès d’autres entreprises. En 2013, la plateforme a entamé un partenariat avec les quatre courtiers de données Acxiom, Epsilon, Datalogix et BlueKai.
« En acquérant plusieurs sociétés de données telles que Datalogix, BlueKai, AddThis et Crosswise, Oracle, déjà l’un des plus grands fournisseurs de logiciels et de bases de données au monde, est ainsi devenu l’un des plus importants courtiers de données de consommation numérique. Dans son nuage de données, Oracle regroupe 3 milliards de profils d’utilisateurs provenant de 15 millions de sites web différents, des données d’1 milliard d’utilisateurs mobiles, de milliards d’achats auprès de chaînes de supermarchés et de 1500 grands détaillants, ainsi que de 700 millions de messages provenant de réseaux sociaux, de blogs et d’avis de consommateurs sur les sites de e-commerce.
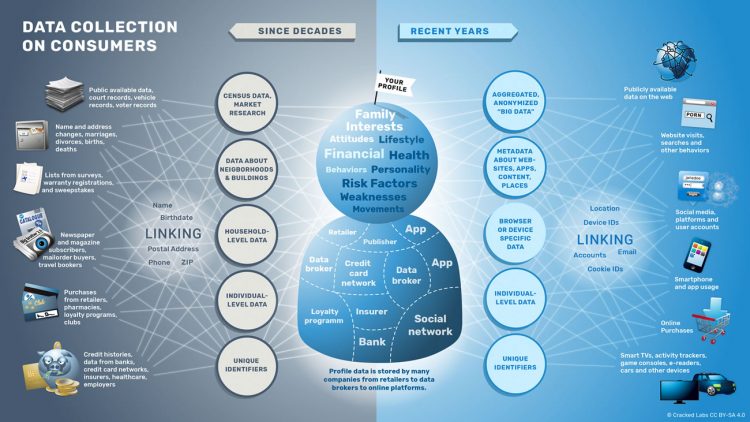
Personnalisation de masse
« Les mouvements quotidiens des consommateurs sur le Web sont également surveillés en temps réel. Pas un mouvement passant par une interface web n’est négligé : des recherches sur Google à celles sur Google Maps, des transports sur Booking jusqu’aux commandes de repas Deliveroo sont exploités dans les transactions des courtiers de données. Des logiciels de cartographie et de datavisualisation sont conçus pour évaluer les données d’un consommateur individuel, qu’elles concernent son passé lointain ou ses dernières actions. Des outils de programmation prospèrent également sur le secteur : il s’agit de vous inonder de suggestions de consommation présentées comme pouvant vous “faciliter” le choix et la vie. (…)
« La société de données Rocket Fuel promet à ses clients de “rassembler des milliards de signaux numériques et réels pour créer des profils individuels et offrir des expériences personnalisées, toujours intéressantes et toujours pertinentes au consommateur”, sur sa base de 2,7 milliards de profils uniques. RocketFuel vend sa “propension à influencer le consommateur”. (…)
« La plateforme de rencontres OkCupid a même sans complexe rapporté une expérience dans laquelle elle a manipulé le pourcentage de “correspondance” indiqué à des paires d’utilisateurs. Affichant une correspondance de 90% à des paires en réalité mauvaises, ces utilisateurs se sont mis à échanger beaucoup plus de messages les uns avec les autres. OkCupid a affirmé que lorsqu’ils “disent aux gens” qu’ils “correspondent bien”, ils “agissent comme si c’était le cas”. (…)
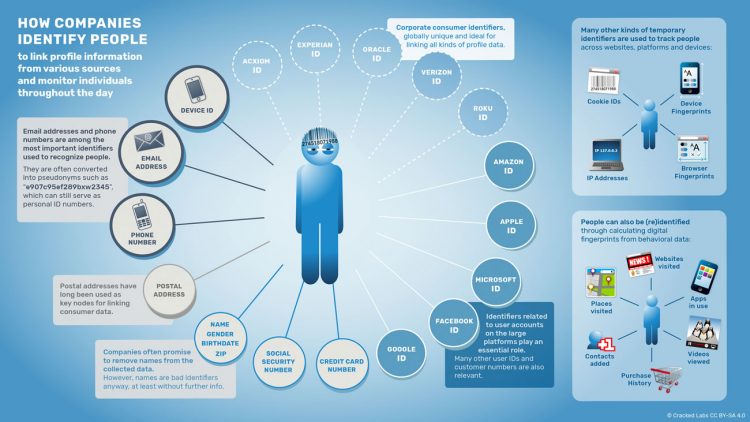
Recoupement des données pro et perso
« En 2012, Facebook a commencé à permettre aux entreprises de télécharger leurs propres listes d’adresses e-mail et de numéros de téléphone sur la plateforme. Bien que ces adresses et ces nombres soient anonymisés, Facebook peut directement lier ces données clients des entreprises aux comptes utilisateurs Facebook des employés. De cette façon, les entreprises peuvent, par exemple, trouver et cibler exactement ces personnes sur Facebook en fonction des adresses e-mail ou des numéros de téléphone. Cette fonctionnalité permet aux entreprises de connecter systématiquement leurs propres données clients avec les données de Facebook et de potentiellement surveiller leur personnel. En outre, il permet également à d’autres vendeurs de publicité et de données de se synchroniser avec les bases de données de la plateforme et de tirer parti de ses capacités, fournissant essentiellement une sorte de contrôle à distance en temps réel de l’univers de données de Facebook.
« Les entreprises peuvent désormais capturer des données comportementales très spécifiques, comme un clic sur un site web, un swipe dans une application mobile ou un achat en magasin, en temps réel, et demander à Facebook de trouver et cibler immédiatement les personnes qui ont effectué ces activités. Google et Twitter ont lancé des fonctionnalités similaires dès 2015.
Le marché de la détection des fraudes
« En plus de la machine de surveillance en temps réel développée dans le cadre de la publicité en ligne, d’autres formes de suivi et de profilage ont vu le jour dans les domaines de l’analyse des risques, de la détection des fraudes et de la cybersécurité. Par exemple, la société de sécurité informatique ThreatMetrix affirme traiter les données sur 1,4 milliard de “comptes d’utilisateurs uniques” dans des “milliers de sites web dans le monde”. Son réseau d’identité numérique capture “des millions de transactions quotidiennes de consommateurs, y compris les connexions, les paiements et les créations nouveaux comptes”, et décrit les “associations en constante évolution entre les personnes et leurs appareils, leurs emplacements, les informations d’identification des comptes et leurs comportements” pour la vérification de l’identité et la prévention de la fraude. Ses clients comprennent notamment Netflix, Visa et des entreprises dans des domaines tels que le jeu, les services gouvernementaux et les services de santé.
« Le reCaptcha de Google est intégré dans des millions de sites et aide les fournisseurs d’accès à détecter si l’internaute est un être humain ou pas. En 2017, Google a introduit une version invisible de reCaptcha qui jusqu’ici vous demandait de cliquer “Je ne suis pas un robot”. Désormais les “utilisateurs humains pourront passer au travers” sans aucune interaction de l’utilisateur, contrairement aux “suspects et robots”. La société ne divulgue pas quel type de données et de comportements elle utilise. Notre enquête suggère que Google ne recourt pas uniquement aux adresses IP, empreintes de navigation et cookies, mais aussi à la manière de taper de l’utilisateur, de déplacer sa souris ou d’utiliser son écran tactile “avant, pendant et après” une interaction reCaptcha. Impossible cependant de savoir si les personnes sans compte d’utilisateur sont défavorisées, si Google est capable d’identifier des individus spécifiques plutôt que de simples “humains”, ou même si Google utilise également les données enregistrées dans reCaptcha à d’autres fins. (…)
Défense des droits civiques
« L’application de la transparence sur les pratiques en matière de données sur les entreprises demeure une condition essentielle pour résoudre les asymétries massives d’information entre les entreprises de données et les particuliers. J’espère que les résultats de ce rapport encourageront les chercheurs, les journalistes et d’autres personnes dans les domaines des droits civiques, de la protection des données, de la protection des consommateurs. »
«Corporate Surveillance in Everyday Life», Cracked Labs (Wolfie Christl, avec Katharina Kopp, Patrick Urs Riechert et illustrations de Pascale Osterwalder), juin 2017